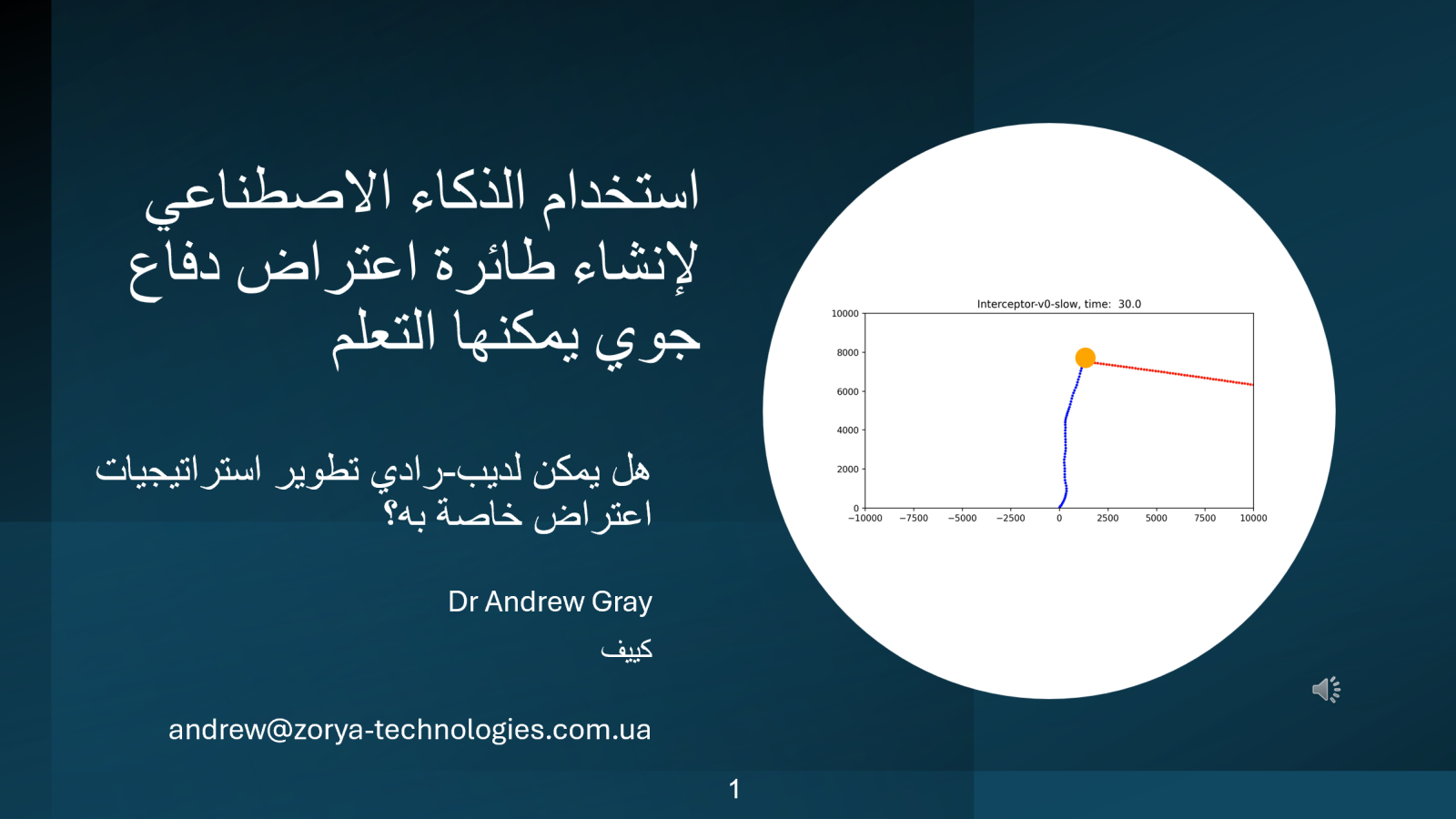
محاكاة الاعتراض باستخدام التعلم المعزز العميق
يتعلم وكيل ذكاء اصطناعي باستخدام التعلم المعزز العميق اعتراض هدف باليستي متحرك في بيئة محاكاة ثنائية الأبعاد.
مشاهدةنظرة عامة
يتناول هذا العرض كيف يمكن لوكيل ذكاء اصطناعي يعتمد على التعلم المعزز العميق (RL) أن يتعلم سياسات الاعتراض ضمن بيئة ثنائية الأبعاد محاكاة.
تتم صياغة المهمة كمشكلة تحكم مستمر يتعلم فيها وكيل ذاتي الوصول إلى هدف متحرك يتبع مساراً باليستياً.
سنرى أن وكيل الذكاء الاصطناعي يطور سياسات اعتراض ناجحة بشكل مستقل، وتختلف هذه السياسات وفقاً للخصائص النسبية لأداء المعترض والهدف.
لمشاهدة المحاكاة الحاسوبية بشكل صحيح، يُفضل عرض هذا الفيديو على شاشة كبيرة مثل الحاسوب المحمول أو الجهاز اللوحي.
اللغات المختلفة
يتم تنفيذ السرد الصوتي لهذا العرض باستخدام ذكاء اصطناعي قمت بتدريبه لاستخدام صوتي وترجمة كلامي إلى لغات أخرى. ينتج هذا الذكاء الاصطناعي تشابهاً جيداً جداً مع صوتي باللغة الإنجليزية، لكن يُقال إن الجودة أقل في بعض اللغات الأخرى.
يمكن اختيار اللغة باستخدام قائمة اختيار اللغة المنسدلة في أعلى الصفحة.
المحتويات
- مشكلة الاعتراض والاستراتيجيات
- معترض يمكنه التعلم من الخبرة
- التعلم المعزز العميق
- تدريب معترض في محاكاة ثنائية الأبعاد
- استراتيجيات الاعتراض بعد التدريب
- الملخص والاستنتاجات
مشكلة الاعتراض
الهدف من هذا العرض هو إظهار كيف يمكن للتعلم المعزز العميق أن يتعلم سلوك الاعتراض في بيئة محاكاة.
في الأمثلة التي سأعرضها، يتحرك الهدف وفق حركة باليستية، ويتم اختيار معاملات مساره بشكل عشوائي في كل محاكاة. وهذا يعني أن وكيل الذكاء الاصطناعي يجب أن يطور سياسة اعتراض عامة فعالة عبر نطاق واسع من المسارات المحتملة للهدف.
في محاكاة التدريب، يتم حساب احتمال نجاح الاعتراض بطريقة احتمالية استناداً إلى المسافة بين الهدف والمعترض في لحظة التفجير. المسافة الصفرية تعني احتمال نجاح بنسبة مئة بالمئة، وينخفض هذا الاحتمال إلى الصفر مع زيادة المسافة.
هل يمكن لوكيل الذكاء الاصطناعي تعلم استراتيجيات اعتراض فعالة؟
سنرى أنه باستخدام التعلم المعزز العميق، يتعلم وكيل الذكاء الاصطناعي سياسة اعتراض فعالة أثناء التدريب. يعتمد نوع الاستراتيجية التي يطورها الذكاء الاصطناعي بشكل كبير على السرعة والتسارع الأقصيين للصاروخ مقارنة بالهدف.
يمكن توسيع هذا الإطار ليشمل أنظمة متعددة الوكلاء أكثر عمومية تتضمن كلاً من المطاردة والمراوغة، حيث يتعلم وكيل الذكاء الاصطناعي كيفية ملاحقة الهدف واعتراضه، بينما يحاول الهدف أيضاً تفادي المعترض.