Моделювання перехоплення з глибоким підкріплювальним навчанням
Агент ШІ з глибоким підкріплювальним навчанням навчається перехоплювати рухому балістичну ціль у змодельованому 2D-середовищі.
ДивитисяОгляд
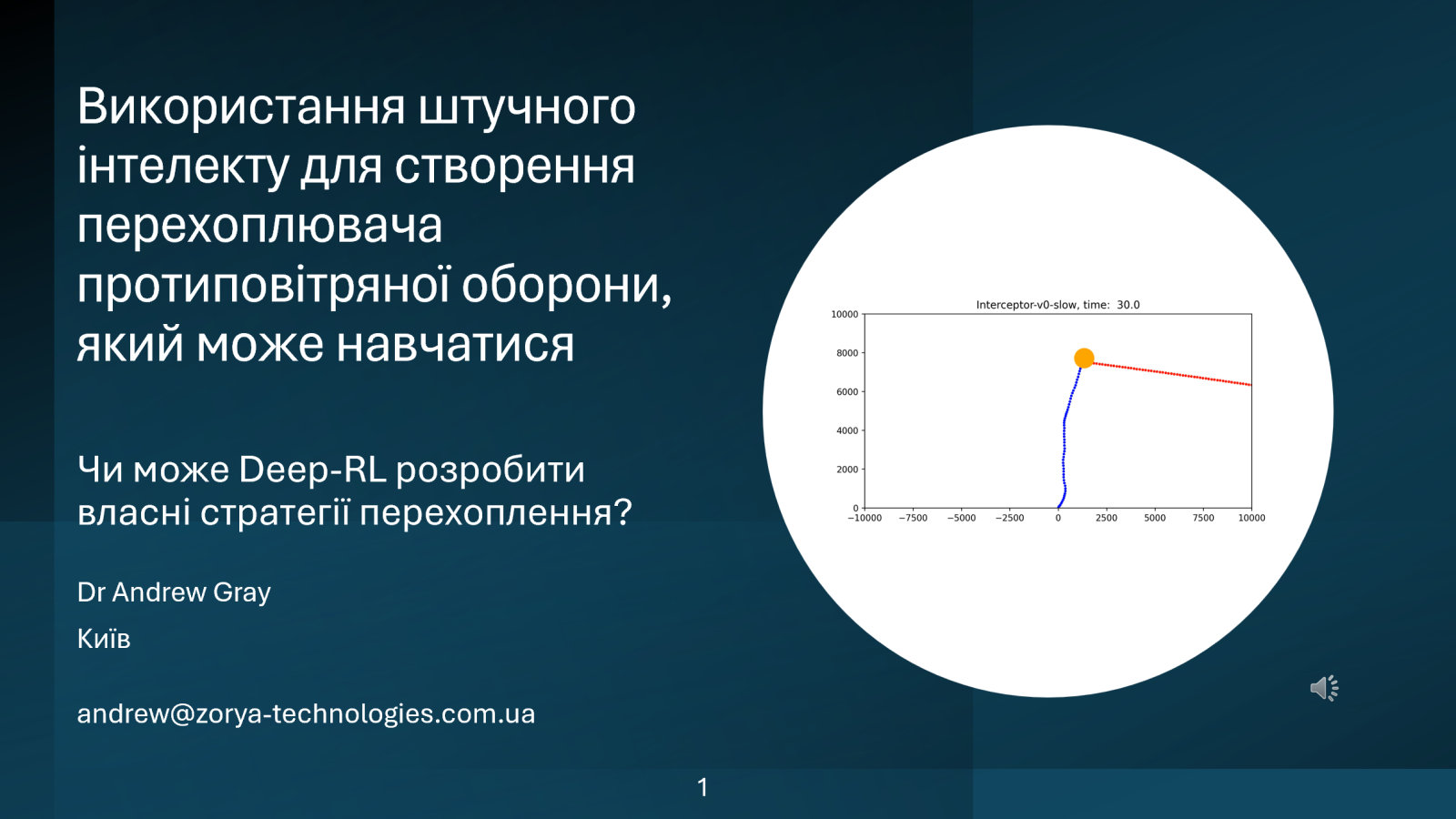
Ця доповідь присвячена тому, як AI-агент глибокого підкріплювального навчання (RL) може навчатися політикам перехоплення у змодельованому двовимірному середовищі.
Завдання формулюється як задача безперервного керування, у якій автономний агент навчається досягати рухомої цілі, що рухається за балістичною траєкторією.
Ми побачимо, що AI-агент самостійно розробляє успішні політики перехоплення, які змінюються залежно від відносних характеристик продуктивності перехоплювача та цілі.
Щоб належним чином переглянути комп’ютерні симуляції, це відео слід дивитися на великому екрані, наприклад на ноутбуці або планшеті.
Різні мовні версії
Озвучення цієї презентації здійснюється за допомогою AI, якого я навчив відтворювати мій голос і перекладати моє мовлення іншими мовами. Цей AI дуже добре відтворює мій голос англійською мовою, але, за наявною інформацією, іншими мовами якість може бути нижчою.
Різні мови можна вибрати за допомогою випадаючого списку вибору мови у верхній частині сторінки.
Зміст
- Проблема перехоплення та стратегії
- Перехоплювач, що може навчатися з досвіду
- Глибоке підкріплювальне навчання
- Навчання перехоплювача у 2-D симуляції
- Стратегії перехоплення після навчання
- Підсумки та висновки
Проблема перехоплення
Мета цієї доповіді — показати, як глибоке RL може навчатися поведінці перехоплення у змодельованому середовищі.
У наведених прикладах ціль рухається за балістичною динамікою, а параметри її траєкторії випадково обираються в кожній симуляції. Це означає, що AI-агент повинен розробити загальну політику перехоплення, ефективну для широкого спектра можливих траєкторій цілі.
У навчальних симуляціях імовірність успішного перехоплення обчислюється ймовірнісно на основі відстані між ціллю та перехоплювачем у момент підриву. Нульова відстань означає стовідсоткову ймовірність успіху, і ця ймовірність зменшується до нуля зі збільшенням відстані.
Чи може AI-агент навчитися ефективних стратегій перехоплення?
Ми побачимо, що, використовуючи Deep-RL, AI-агент успішно навчається ефективної політики перехоплення під час навчання. Тип стратегії, розроблений AI, значною мірою залежить від максимальної швидкості та прискорення ракети відносно цілі.
Такий підхід можна розширити до більш загальних багатoагентних систем, що включають як переслідування, так і ухилення, де AI-агент навчається переслідувати й перехоплювати ціль, тоді як ціль також намагається уникнути перехоплення.